Zastosowanie
Nożyco-rozpieracz jest narzędziem hydraulicznym przewidzianym do cięcia, rozpierania, a po połączeniu z zespołem łańcuchów do ciągnięcia.
Urządzenie zostało zaprojektowane w pierwszym rzędzie do zastosowań ratowniczych. W ten sposób np. osoby zablokowane w czasie wypadków komunikacyjnych mogą być szybko i bez dalszego zagrożenia uwolnione przez wyważenie drzwi samochodowych, odcięcie konstrukcji dachowej, odciągnięcie kolumny kierowniczej itp.
Cięcie – Nożyco-rozpieracz ma dwie możliwości cięcia. Ostrza o specjalnym uzębieniu nadają się szczególnie do przecinania blach stalowych i prętów profilowanych. Pręty okrągłe przecina się za pomocą ostrza do cięcia materiałów okrągłych.
Podczas rozpierania i ciągnięcia postępujemy identycznie jak w przypadku rozpieraczy ramionowych.
Budowa
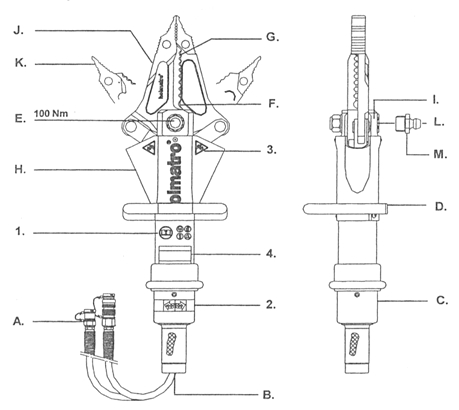
Rys. 25 Schemat budowy nożyco-rozpieraczy marki Holmatro.
Oznaczenia symboli
- Szybkozłącza
- Zawory nadmiarowe bezpieczeństwa
- Uchwyt sterujący
- Rączka do trzymania
- Śruba centralna
- Otwór do cięcia
- Krawędź tnąca
- Osłona
- Jarzmo
- Ramiona
- Końcówki rozpierające
- Kanał smarowniczy
- Końcówka smarownicza
Zasady bezpieczeństwa
- Noś sprzęt ochrony osobistej
- Kierunek działania uchwytu sterującego
- Ostrzeżenie o ściśnięciu/odcięciu części korpusu
- Informacje o produkcie: model, nr seryjny, rok budowy, itp.
Parametry techniczne
| Firma | HOLMATRO
z pompą ręczną |
LUCAS | VEBER HYDRAULIK | ||||||
| Model | CT 3110 | CT 3150 | ZESTAW CT 3113 | LKS 35C | UNITOL LKS 30 | LKE 50 | SPS 330L | SPS 330A | SPS 250H |
| Max rozparcie (mm) | 194 | 360 | 194 | 360 | 330 | 330 | 250 | ||
| Max siła rozpierania przy otwartych ramionach (ton) | 5,4 | 8,7 | 5,4 | 8,0 | 5,2 | 5,2 | 9,0 | 9,0 | 8,3 |
| Max rozwarcie ostrzy (mm) | 110 | 230 | 110 | 160 | 200 | ||||
| Max siła cięcia (w zagłęb.) (ton) | 30 | 35,5 | 30 | 30 | 13,5 | 13,5 | 25 | 25 | 22 |
| Siła cięcia w środku ostrzy (ton) | 11 | 12,7 | 11 | ||||||
| Max siła ściskania między końcówkami (ton) | 7,3 | 7,6 | 7,3 | ||||||
| Waga (kg) | 14 | 15,8 | 14/39
z pompą |
15,5 | 11,5 | 14,6 | 13 | 17 | 10,4 |
Metodyka postępowania
Obsługa nożyco-rozpieraczy jest połączeniem obsług nożyc i rozpieraczy.
Cięcie narzędziem uniwersalnym ma dwie możliwości. Ostrza o specjalnym uzębieniu nadają się szczególnie do przecinania blach stalowych i prętów profilowanych. Pręty okrągłe przecina się za pomocą ostrza do cięcia materiałów okrągłych. W celu uniknięcia obrotu i zakleszczenia się materiału ciętego między ramionami noży (grozi to uszkodzeniem ramion noży), należy zwrócić uwagę na:
- materiał cięty powinien znajdować się położeniu prostopadłym do powierzchni,
- w razie potrzeby zamocować materiał cięty.
Wyższe wydajności cięcia uzyskuje się, gdy cięcie jest dokonywane możliwie w pobliżu ostrza do cięcia przekrojów okrągłych.
Cięcie stali sprężynowej (np. piór resorów i drążków kierowniczych pojazdów samochodowych) jest niedopuszczalne ze względu na niebezpieczeństwo odprysków ciętego materiału i związane z tym zagrożenie osoby poszkodowanej i operatora, poza tym uszkodzeniu mogą ulec ramiona noży.
W razie użycia narzędzia do podnoszenia przedmiotów w żadnym wypadku nie wolno pracować pod podniesionym ciężarem. Rozpieranie i ciągnięcie narzędziem odbywa się tak samo jak już to opisywałem w obsłudze rozpieracza.
Po każdorazowym użyciu ramiona należy zamknąć do pozycji rozwarcia ostrzy około 15 mm. Dzięki temu urządzenie jest obciążone hydraulicznie i mechanicznie.
W celu zapobieżenia zabrudzeniu, złącza muszą być po odłączeniu urządzenia zamknięte kapturkami ochronnymi, bądź zwarte ze sobą.
Zalecenia dotyczące bezpieczeństwa
Przed przystąpieniem do obsługi należy:
- zapoznać się dokładnie z instrukcją obsługi
- stosować ubrania robocze lub ochronne:
- hełm ochronny z wizjerem lub okularami ochronnymi
- rękawice ochronne
- kombinezon ochronny
- osoby postronne utrzymywać w bezpiecznej odległości
- stać na stabilnym gruncie i obsługiwać sprzęt obiema rękami
- trzymać narzędzie narzędzie tylko w miejscach na to przeznaczonych
- ustabilizować obiekt, który jest przedmiotem działania
- w przypadku wycieku oleju natychmiast przerwać pracę
- nastawione na stałe ciśnienie maksymalne nie może być w żadnym wypadku zmieniane
- dozwolone jest stosowanie tylko oryginalnych części zamiennych
- przestrzegać terminów przeglądów o konserwacji
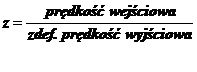
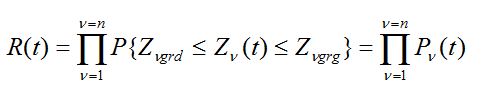 (44)
(44)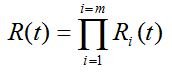 (45)
(45)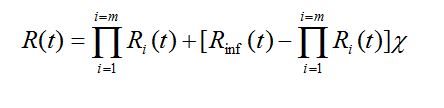
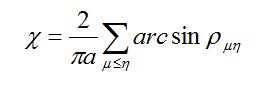
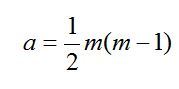 (47)
(47)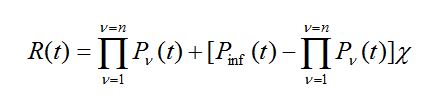 (48)
(48)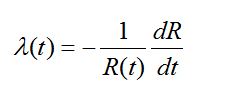 (49)
(49)